Puntos de control
Enable the Data Catalog API
/ 10
Create the SQLServer Database
/ 10
Set Up the Service Account for SQLServer
/ 10
Execute SQLServer to Data Catalog connector
/ 10
Create the PostgreSQL Database
/ 10
Create a Service Account for postgresql
/ 10
Execute PostgreSQL to Data Catalog connector
/ 10
Create the MySQL Database
/ 10
Create a Service Account for MySQL
/ 10
Execute MySQL to Data Catalog connector
/ 10
Cómo compilar y ejecutar MySQL, PostgreSQL y SQL Server en los conectores de Data Catalog
GSP814

Descripción general
Dataplex es un tejido de datos inteligente que permite a las organizaciones descubrir, administrar, supervisar y controlar de forma centralizada sus datos en todos los data lakes, almacenes de datos y data marts para potenciar la analítica a gran escala.
Data Catalog es un servicio de administración de metadatos escalable y completamente administrado dentro de Dataplex. Ofrece una interfaz de búsqueda simple y fácil de usar para descubrir datos, y un sistema de catalogación flexible y potente que permite capturar metadatos técnicos y empresariales. Además, brinda una base sólida de seguridad y cumplimiento gracias a las integraciones en Cloud Data Loss Prevention (DLP) y Cloud Identity and Access Management (IAM).
Usa Data Catalog
Con Data Catalog en Dataplex, puedes buscar los recursos a los que tienes acceso y etiquetar los recursos de datos para admitir el descubrimiento y el control de acceso. Las etiquetas permiten conectar campos de metadatos personalizados a recursos de datos específicos para facilitar la identificación y la recuperación (por ejemplo, etiquetar determinados recursos para indicar que tienen datos protegidos o sensibles). También puedes crear plantillas de etiquetas reutilizables para asignar de manera rápida las mismas etiquetas a diferentes recursos de datos.
Objetivos
En este lab, aprenderás a hacer lo siguiente:
- Habilitar la API de Data Catalog
- Configurar los conectores de Dataplex para SQL Server, PostgreSQL y MySQL
- Buscar entradas de SQL Server, PostgreSQL y MySQL en Data Catalog dentro de Dataplex
Requisitos previos
Configuración y requisitos
Antes de hacer clic en el botón Comenzar lab
Lee estas instrucciones. Los labs son cronometrados y no se pueden pausar. El cronómetro, que comienza a funcionar cuando haces clic en Comenzar lab, indica por cuánto tiempo tendrás a tu disposición los recursos de Google Cloud.
Este lab práctico te permitirá realizar las actividades correspondientes en un entorno de nube real, no en uno de simulación o demostración. Para ello, se te proporcionan credenciales temporales nuevas que utilizarás para acceder a Google Cloud durante todo el lab.
Para completar este lab, necesitarás lo siguiente:
- Acceso a un navegador de Internet estándar (se recomienda el navegador Chrome)
- Tiempo para completar el lab: Recuerda que, una vez que comienzas un lab, no puedes pausarlo.
Cómo iniciar su lab y acceder a la consola de Google Cloud
-
Haga clic en el botón Comenzar lab. Si debe pagar por el lab, se abrirá una ventana emergente para que seleccione su forma de pago. A la izquierda, se encuentra el panel Detalles del lab que tiene estos elementos:
- El botón Abrir la consola de Google
- Tiempo restante
- Las credenciales temporales que debe usar para el lab
- Otra información para completar el lab, si es necesaria
-
Haga clic en Abrir la consola de Google. El lab inicia recursos y abre otra pestaña en la que se muestra la página de acceso.
Sugerencia: Ordene las pestañas en ventanas separadas, una junto a la otra.
Nota: Si ve el diálogo Elegir una cuenta, haga clic en Usar otra cuenta. -
Si es necesario, copie el nombre de usuario del panel Detalles del lab y péguelo en el cuadro de diálogo Acceder. Haga clic en Siguiente.
-
Copie la contraseña del panel Detalles del lab y péguela en el cuadro de diálogo de bienvenida. Haga clic en Siguiente.
Importante: Debe usar las credenciales del panel de la izquierda. No use sus credenciales de Google Cloud Skills Boost. Nota: Usar su propia Cuenta de Google podría generar cargos adicionales. -
Haga clic para avanzar por las páginas siguientes:
- Acepte los términos y condiciones.
- No agregue opciones de recuperación o autenticación de dos factores (esta es una cuenta temporal).
- No se registre para obtener pruebas gratuitas.
Después de un momento, se abrirá la consola de Cloud en esta pestaña.

Activa Cloud Shell
Cloud Shell es una máquina virtual que cuenta con herramientas para desarrolladores. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud. Cloud Shell proporciona acceso de línea de comandos a tus recursos de Google Cloud.
- Haz clic en Activar Cloud Shell
en la parte superior de la consola de Google Cloud.
Cuando te conectes, habrás completado la autenticación, y el proyecto estará configurado con tu PROJECT_ID. El resultado contiene una línea que declara el PROJECT_ID para esta sesión:
gcloud es la herramienta de línea de comandos de Google Cloud. Viene preinstalada en Cloud Shell y es compatible con la función de autocompletado con tabulador.
- Puedes solicitar el nombre de la cuenta activa con este comando (opcional):
-
Haz clic en Autorizar.
-
Ahora, el resultado debería verse de la siguiente manera:
Resultado:
- Puedes solicitar el ID del proyecto con este comando (opcional):
Resultado:
Resultado de ejemplo:
gcloud, consulta la guía con la descripción general de gcloud CLI en Google Cloud.
Tarea 1: Habilita la API de Data Catalog
-
Abre el menú de navegación y selecciona APIs y servicios > Biblioteca.
-
En la barra de búsqueda, ingresa “Data Catalog” y selecciona la
API de Data Catalog de Google Cloud. -
Haz clic en Habilitar.
Haz clic en Revisar mi progreso para verificar el objetivo.
Tarea 2: SQL Server en Dataplex
Para comenzar, configura el entorno.
-
Para abrir una sesión nueva de Cloud Shell, haz clic en el ícono Activar Cloud Shell en la parte superior derecha de la consola:
-
Ejecuta el siguiente comando para configurar tu ID del proyecto como una variable de entorno:
Crea la base de datos de SQL Server
- En tu sesión de Cloud Shell, ejecuta el siguiente comando para descargar las secuencias de comandos y, luego, crear y propagar la instancia de SQL Server:
- Ahora, cambia el directorio de trabajo actual al que descargaste:
- Ejecuta el siguiente comando para cambiar la región
us-central1por la región que tienes asignada de manera predeterminada:
- Ahora, ejecuta la secuencia de comandos
init-db.sh.
Se creará tu instancia de SQL Server y se propagará con un esquema aleatorio.
Error: Failed to load "tfplan" as a plan file, vuelve a ejecutar la secuencia de comandos init-db.
Este proceso tardará entre 5 y 10 minutos en completarse. Podrás continuar cuando recibas el siguiente resultado:
Haz clic en Revisar mi progreso para verificar el objetivo.
Configura la cuenta de servicio
- Ejecuta el siguiente comando para crear una cuenta de servicio:
- A continuación, crea y descarga la clave de la cuenta de servicio.
- Agrega el rol Administrador de Data Catalog a la cuenta de servicio:
Haz clic en Revisar mi progreso para verificar el objetivo.
Ejecuta SQL Server en el conector de Dataplex
Puedes compilar el conector de SQL Server por tu cuenta; para ello, ve a este repositorio de GitHub.
Para facilitar su uso, usaremos una imagen de Docker.
La configuración de Terraform generó las variables necesarias.
- Cambia de directorio a la ubicación de las secuencias de comandos de Terraform:
- Obtén las variables de entorno:
- Vuelve a cambiar al directorio raíz para el código de ejemplo:
- Usa el siguiente comando para ejecutar el conector:
Algunos segundos después, deberías obtener el siguiente resultado:
Haz clic en Revisar mi progreso para verificar el objetivo.
Busca las entradas de SQL Server en Dataplex
-
Después de que finalice la secuencia de comandos, abre el menú de navegación y selecciona Dataplex en la lista de servicios.
-
En la página Dataplex, haz clic en Plantilla de etiquetas.
Deberías ver la lista de Plantillas de etiquetas de sqlserver.
- Luego, selecciona Grupos de entrada.
Deberías ver el grupo de entrada sqlserver en la lista Grupos de entrada:
- Ahora, haz clic en el grupo de entrada
sqlserver. La consola debería verse de la siguiente manera:
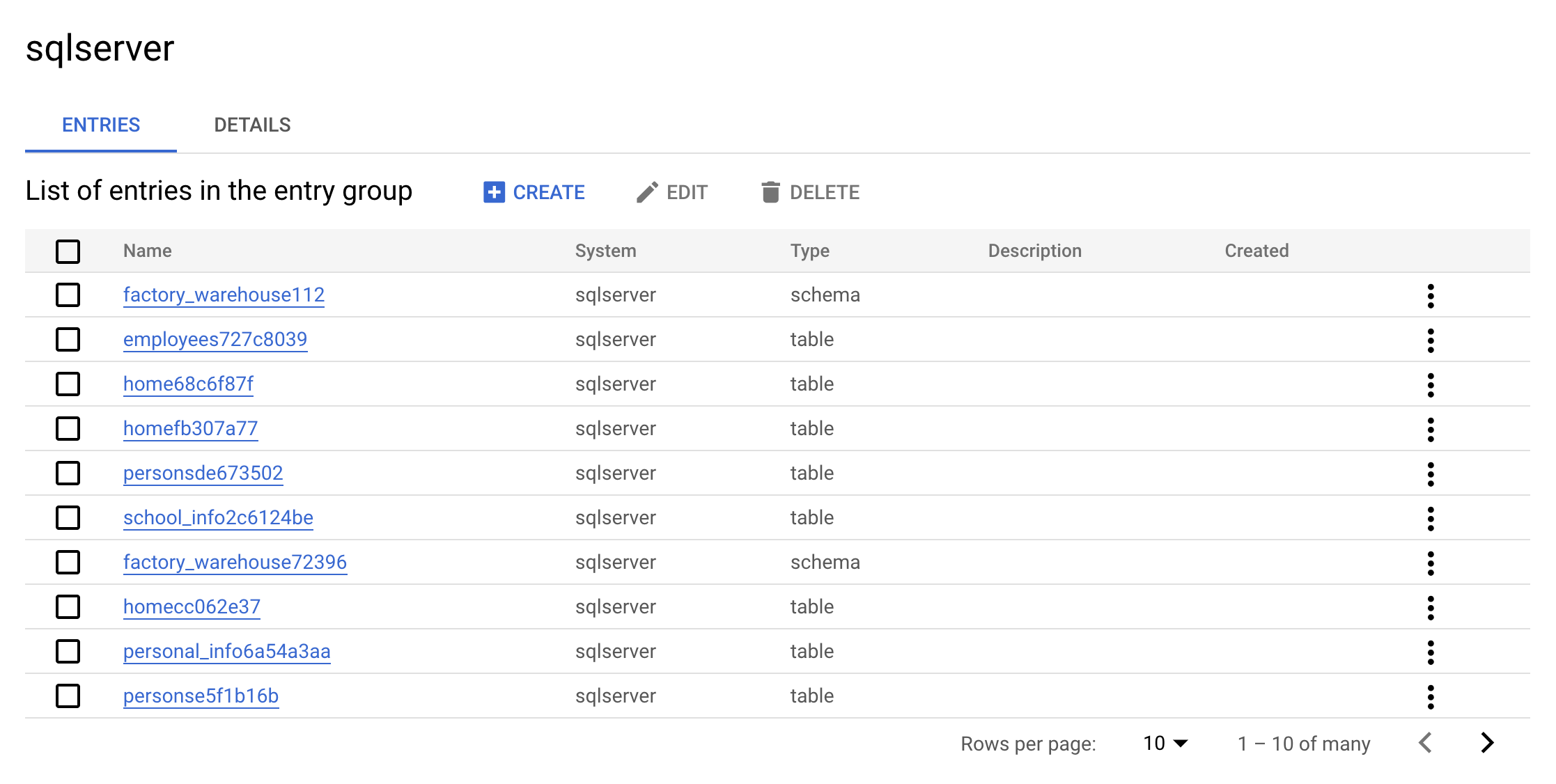
Este es el valor real de un grupo de entrada. Puedes ver todas las entradas que pertenecen a sqlserver usando la IU.
- Haz clic en una de las entradas que contenga la palabra
warehouse. Consulta los detalles y las etiquetas de entrada personalizados.
Este es el valor real que agrega el conector. Te permite buscar metadatos en Dataplex.
Realiza una limpieza
- Para borrar los recursos que creaste, ejecuta el siguiente comando para eliminar los metadatos de SQL Server:
- Ahora, ejecuta el contenedor para realizar la limpieza:
- Ahora, ejecuta el siguiente comando para borrar la base de datos de SQL Server:
-
En el menú de navegación, haz clic en Dataplex.
-
Busca sqlserver.
Ya no verás las plantillas de etiqueta de SQL Server en los resultados:
Antes de continuar, asegúrate de obtener el siguiente resultado en Cloud Shell:
Ahora aprenderás a hacer lo mismo con una instancia de PostgreSQL.
Tarea 3: PostgreSQL en Dataplex
Crea la base de datos de PostgreSQL
- En Cloud Shell, ejecuta el siguiente comando para regresar al directorio principal:
- Ejecuta el siguiente comando para clonar el repositorio de GitHub:
- Ahora, cambia el directorio de trabajo actual al directorio del repositorio clonado:
- Ejecuta el siguiente comando para cambiar la región
us-central1por la región que tienes asignada de manera predeterminada:
- Ejecuta la secuencia de comandos
init-db.sh:
Se creará tu instancia de PostgreSQL y se propagará con un esquema aleatorio, lo que puede tardar entre 10 y 15 minutos en completarse.
Error: Failed to load "tfplan" as a plan file, vuelve a ejecutar la secuencia de comandos init-db.
Algunos segundos después, deberías obtener el siguiente resultado:
Haz clic en Revisar mi progreso para verificar el objetivo.
Configura la cuenta de servicio
- Crea una cuenta de servicio:
- A continuación, crea y descarga la clave de la cuenta de servicio:
- Agrega el rol Administrador de Data Catalog a la cuenta de servicio:
Haz clic en Revisar mi progreso para verificar el objetivo.
Ejecuta PostgreSQL en un conector de Dataplex
Puedes compilar el conector de PostgreSQL por tu cuenta desde este repositorio de GitHub.
Para facilitar su uso, usaremos una imagen de Docker.
La configuración de Terraform generó las variables necesarias.
- Cambia de directorio a la ubicación de las secuencias de comandos de Terraform:
- Obtén las variables de entorno:
- Vuelve a cambiar al directorio raíz para el código de ejemplo:
- Ejecuta el conector:
Algunos segundos después, deberías obtener el siguiente resultado:
Haz clic en Revisar mi progreso para verificar el objetivo.
Verifica los resultados de la secuencia de comandos
-
Asegúrate de estar en la página principal de Dataplex.
-
Haz clic en Plantillas de etiquetas.
Deberías ver las siguientes plantillas de etiquetas de postgresql:

- Haz clic en Grupos de entrada.
Deberías ver el siguiente grupo de entrada de postgresql:

- Ahora, haz clic en el grupo de entrada
postgresql. La consola debería verse de la siguiente manera:
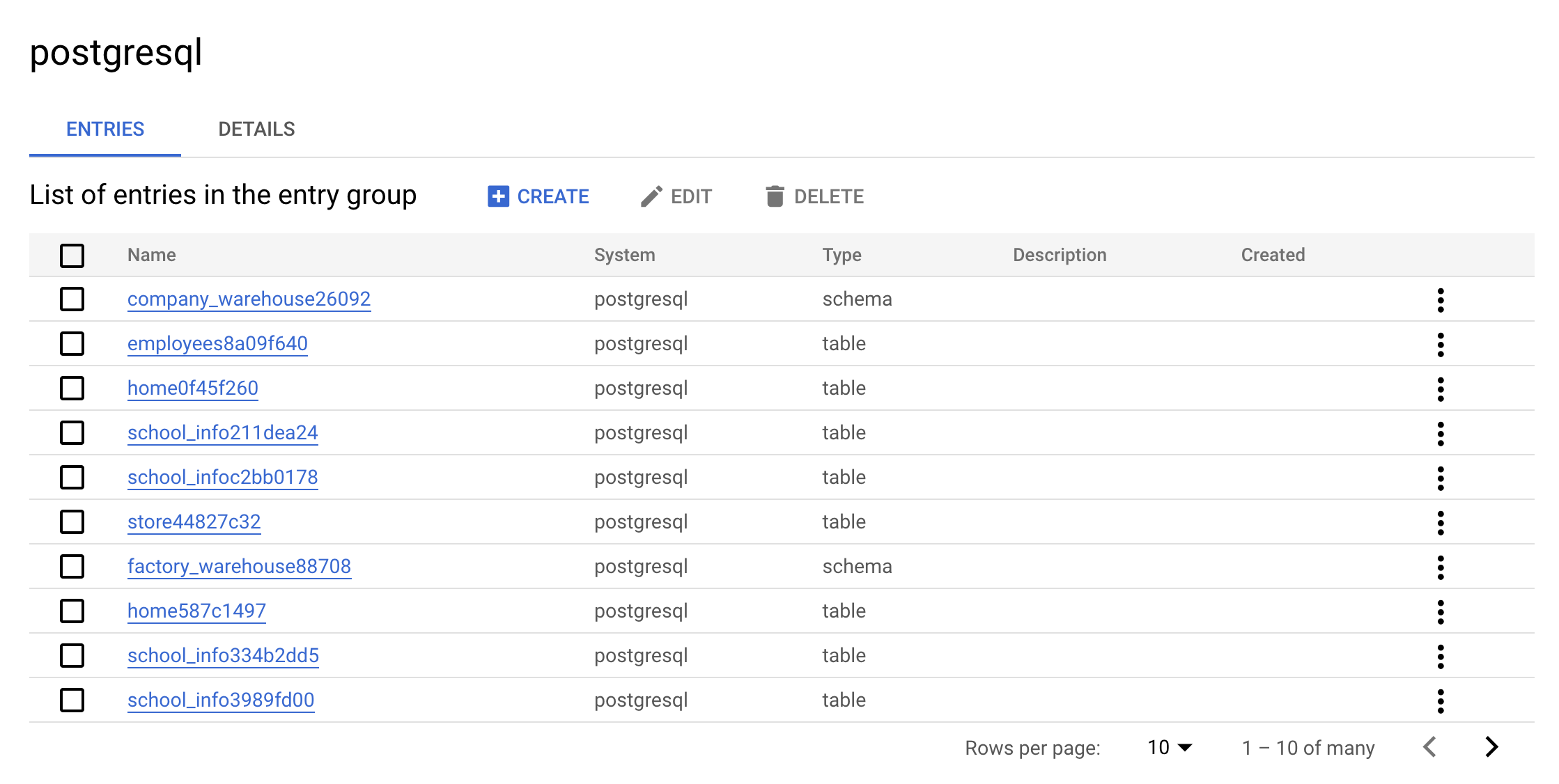
Este es el valor real de un grupo de entrada. Puedes ver todas las entradas que pertenecen a postgresql mediante la IU.
- Haz clic en una de las entradas que contenga la palabra
warehouse. Consulta los detalles y etiquetas de entrada personalizados:
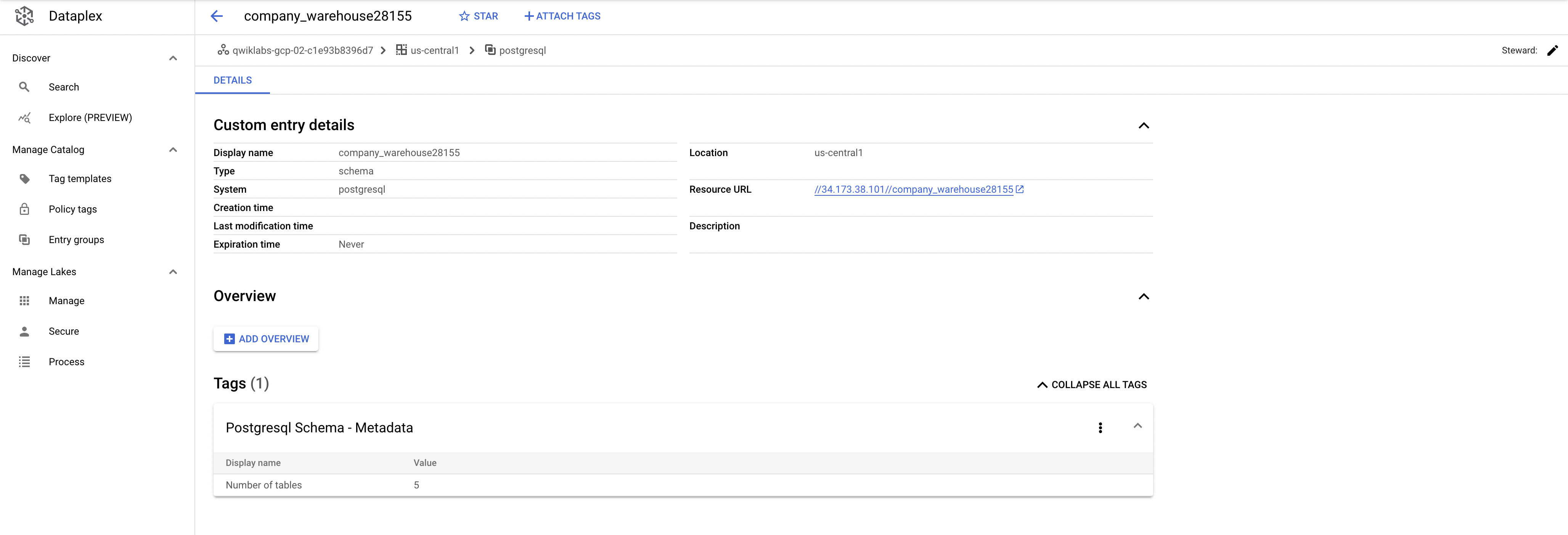
Este es el valor real que agrega el conector. Te permite buscar metadatos en Dataplex.
Realiza una limpieza
- Para borrar los recursos que creaste, ejecuta el siguiente comando y borra los metadatos de PostgreSQL:
- Ahora, ejecuta el contenedor para realizar la limpieza:
- Por último, borra la base de datos de PostgreSQL:
-
Ahora, en el menú de navegación, haz clic en Dataplex.
-
Busca PostgreSQL. Ya no verás las plantillas de etiqueta de PostgreSQL en los resultados:
Antes de continuar, asegúrate de obtener el siguiente resultado en Cloud Shell:
Ahora, aprenderás a hacer lo mismo con una instancia de MySQL.
Tarea 4: MySQL en Dataplex
Crea la base de datos de MySQL
- En Cloud Shell, ejecuta el siguiente comando para regresar al directorio principal:
- Ejecuta el siguiente comando para descargar las secuencias de comandos y, luego, crear y propagar la instancia de MySQL:
- Ahora, cambia el directorio de trabajo actual al directorio del repositorio clonado:
- Ejecuta el siguiente comando para cambiar la región
us-central1por la región que tienes asignada de manera predeterminada:
- Ejecuta la secuencia de comandos
init-db.sh:
Se creará tu instancia de MySQL y se propagará con un esquema aleatorio. Luego de unos minutos, deberías recibir el siguiente resultado:
Error: Failed to load "tfplan" as a plan file, vuelve a ejecutar la secuencia de comandos init-db.
Haz clic en Revisar mi progreso para verificar el objetivo.
Configura la cuenta de servicio
- Ejecuta lo siguiente para crear una cuenta de servicio:
- A continuación, crea y descarga la clave de la cuenta de servicio:
- Agrega el rol Administrador de Data Catalog a la cuenta de servicio:
Haz clic en Revisar mi progreso para verificar el objetivo.
Ejecuta MySQL en un conector de Dataplex
Puedes compilar el conector de MySQL tú mismo si te diriges a este repositorio de GitHub.
Para facilitar su uso, en este lab se utiliza una imagen de Docker.
La configuración de Terraform generó las variables necesarias.
- Cambia de directorio a la ubicación de las secuencias de comandos de Terraform:
- Obtén las variables de entorno:
- Vuelve a cambiar al directorio raíz para el código de ejemplo:
- Ejecuta el conector:
Algunos segundos después, deberías obtener el siguiente resultado:
Haz clic en Revisar mi progreso para verificar el objetivo.
Verifica los resultados de la secuencia de comandos
-
Asegúrate de estar en la página principal de Dataplex.
-
Haz clic en Plantillas de etiquetas.
Deberías ver las siguientes plantillas de etiquetas de mysql:

- Haz clic en Grupos de entrada.
Deberías ver el siguiente grupo de entrada de mysql:

- Ahora, haz clic en el grupo de entrada
mysql. La consola debería verse de la siguiente manera:
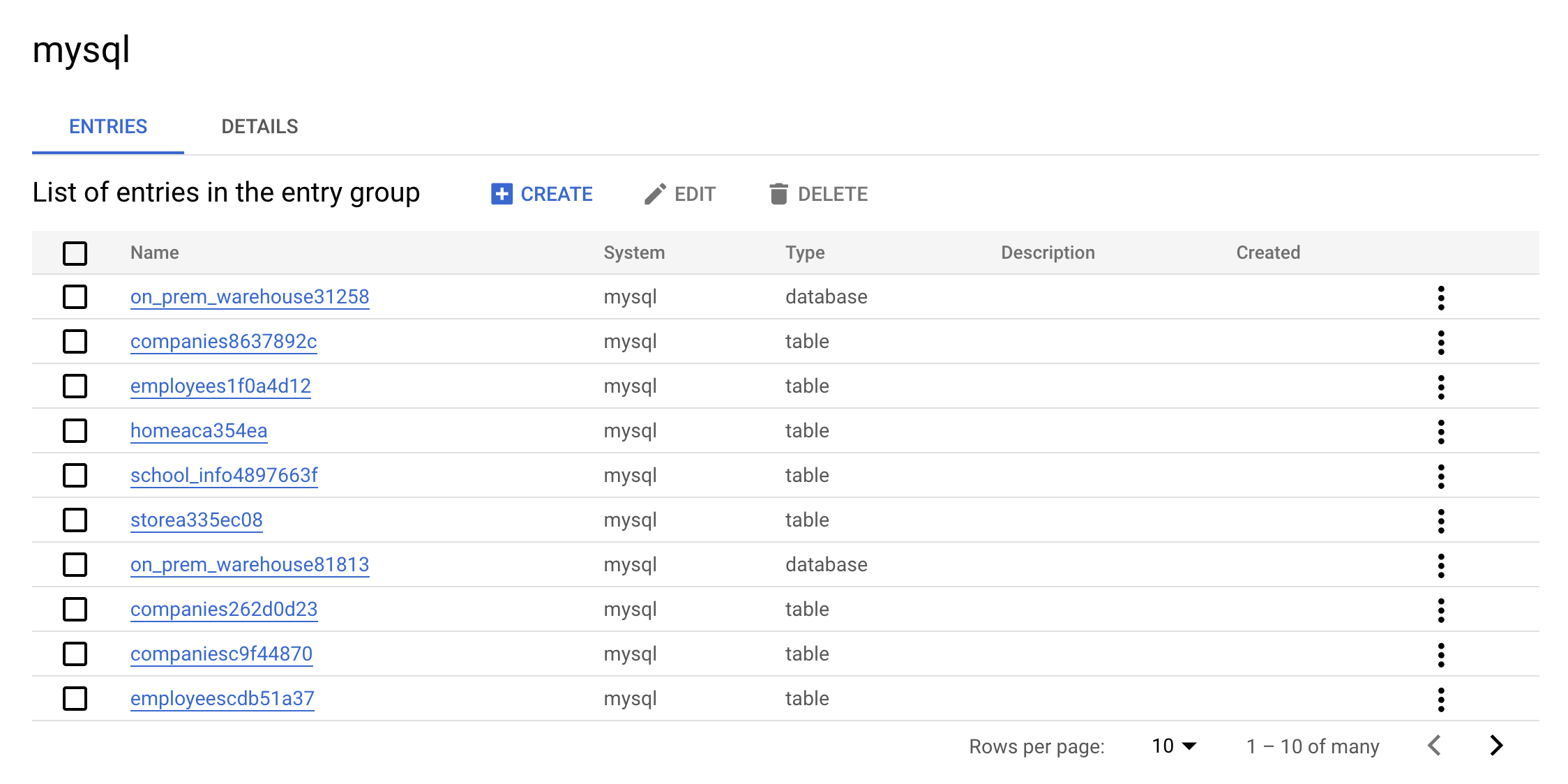
Este es el valor real de un grupo de entrada. Puedes ver todas las entradas que pertenecen a MySQL mediante la IU.
- Haz clic en una de las entradas que contenga la palabra
warehouse. Consulta los detalles y las etiquetas de entrada personalizados.
Este es el valor real que agrega el conector. Te permite buscar metadatos en Dataplex.
Realiza una limpieza
- Para borrar los recursos que creaste, ejecuta el siguiente comando y borra los metadatos de MySQL:
- Ahora, ejecuta el contenedor para realizar la limpieza:
- Por último, borra la base de datos de PostgreSQL:
-
En el menú de navegación, haz clic en Dataplex.
-
Busca MySQL. Ya no verás las plantillas de etiquetas de MySQL en los resultados.
Antes de continuar, asegúrate de obtener el siguiente resultado en Cloud Shell:
¡Felicitaciones!
¡Felicitaciones! En este lab, aprendiste a compilar y ejecutar MySQL, PostgreSQL y SQL Server en los conectores de Dataplex. También aprendiste a buscar entradas de SQL Server, PostgreSQL y MySQL en Data Catalog dentro de Dataplex. Ahora puedes usar estos conocimientos para compilar tus propios conectores.
Finaliza el curso
Este lab de autoaprendizaje forma parte de los cursos BigQuery for Data Warehousing, BigQuery for Marketing Analysts y Data Catalog Fundamentals. Consulta el catálogo de Google Cloud Skills Boost para ver todos los cursos disponibles.
Próximos pasos y más información
- Consulta la descripción general de Data Catalog
- Obtén información sobre cómo buscar con el Data Catalog
- Explora la descripción general de las APIs y las bibliotecas cliente
Capacitación y certificación de Google Cloud
Recibe la formación que necesitas para aprovechar al máximo las tecnologías de Google Cloud. Nuestras clases incluyen habilidades técnicas y recomendaciones para ayudarte a avanzar rápidamente y a seguir aprendiendo. Para que puedas realizar nuestros cursos cuando más te convenga, ofrecemos distintos tipos de capacitación de nivel básico a avanzado: a pedido, presenciales y virtuales. Las certificaciones te ayudan a validar y demostrar tus habilidades y tu conocimiento técnico respecto a las tecnologías de Google Cloud.
Última actualización del manual: 17 de octubre de 2023
Prueba más reciente del lab: 17 de octubre de 2023
Copyright 2024 Google LLC. All rights reserved. Google y el logotipo de Google son marcas de Google LLC. Los demás nombres de productos y empresas pueden ser marcas de las respectivas empresas a las que estén asociados.