Checkpoints
Enable the Data Catalog API
/ 10
Create the SQLServer Database
/ 10
Set Up the Service Account for SQLServer
/ 10
Execute SQLServer to Data Catalog connector
/ 10
Create the PostgreSQL Database
/ 10
Create a Service Account for postgresql
/ 10
Execute PostgreSQL to Data Catalog connector
/ 10
Create the MySQL Database
/ 10
Create a Service Account for MySQL
/ 10
Execute MySQL to Data Catalog connector
/ 10
Criar e executar os conectores MySQL, PostgreSQL e SQLServer para o Data Catalog
GSP814

Visão geral
O Dataplex é a malha de dados inteligente que as organizações usam para conhecer, gerenciar, monitorar e supervisionar em um só lugar os dados em data lakes, data warehouses e data marts permitindo análises em escala.
O Data Catalog é um serviço de metadados totalmente gerenciado e escalonável no Dataplex. Ele tem uma interface de pesquisa simples e fácil de usar para descoberta de dados, um sistema de catalogação flexível e avançado para capturar metadados técnicos e comerciais, além de uma base sólida de segurança e compliance integrada ao Cloud Data Loss Prevention (DLP) e ao Cloud Identity and Access Management (IAM).
Como usar o Data Catalog
Com o Data Catalog no Dataplex, é possível pesquisar ativos a que você tem acesso e marcar ativos de dados para dar suporte à descoberta e ao controle de acesso. As tags permitem anexar campos de metadados personalizados a ativos de dados específicos para fácil identificação e recuperação (por exemplo, marcar que determinados ativos têm dados protegidos ou sensíveis). Também é possível criar modelos de tags reutilizáveis para atribuição rápida das mesmas tags a diferentes ativos de dados.
Objetivos
Neste laboratório, você vai aprender o seguinte:
- Ativar a API Data Catalog.
- Configurar os conectores do Dataplex para SQL Server, PostgreSQL e MySQL.
- Pesquisar as entradas do SQL Server, do PostgreSQL e do MySQL no Data Catalog do Dataplex.
Pré-requisitos
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Tarefa 1. Ativar a API Data Catalog
-
Abra o menu de navegação e selecione APIs e serviços > Biblioteca.
-
Na barra de pesquisa insira "Data Catalog" e selecione
Google Cloud Data Catalog API. -
Depois clique em Ativar.
Clique em Verificar meu progresso para conferir o objetivo.
Tarefa 2. SQL Server para Dataplex
Primeiro configure seu ambiente.
-
Clique no ícone Ativar o Cloud Shell no canto superior direito do console para abrir uma nova sessão do Cloud Shell:
-
Execute o seguinte comando para definir o ID do projeto como uma variável de ambiente:
Criar o banco de dados do SQL Server
- Na sessão do Cloud Shell, execute o seguinte comando para fazer o download dos scripts para criar e preencher a instância do SQL Server:
- Mude o diretório de trabalho atual para o diretório salvo:
- Execute o seguinte comando para alterar de
us-central1para a região padrão atribuída a você:
- Agora execute o script
init-db.sh.
Isso cria e preenche a instância do SQL Server com um esquema aleatório.
Error: Failed to load "tfplan" as a plan file for exibido, execute de novo o script init-db.
Esse procedimento pode levar de 5 a 10 minutos para ser concluído. Será possível continuar quando receber a seguinte resposta:
Clique em Verificar meu progresso para conferir o objetivo.
Configurar a conta de serviço
- Execute o seguinte comando para criar uma conta de serviço:
- Crie e faça o download da chave da conta de serviço.
- Adicione o papel de administrador do Data Catalog à conta de serviço:
Clique em Verificar meu progresso para conferir o objetivo.
Executar o conector do SQL Server para o Dataplex
Para criar o conector do SQL Server, acesse este repositório do GitHub.
Para facilitar, você usará uma imagem Docker.
As variáveis necessárias foram geradas pela configuração do Terraform.
- Migre os diretórios para o local dos scripts do Terraform:
- Copie as seguintes variáveis de ambiente:
- Retorne ao diretório raiz do código de exemplo:
- Use o seguinte comando para executar o conector:
Logo depois, você receberá a seguinte resposta:
Clique em Verificar meu progresso para conferir o objetivo.
Pesquisar as entradas do SQL Server no Dataplex
-
Após o script ser concluído, abra o menu de navegação e selecione Dataplex na lista de serviços.
-
Na página Dataplex, clique em Modelos de tag.
Vai aparecer uma lista de modelos de tag do sqlserver.
- Em seguida, selecione Grupos de entradas.
O grupo de entradas sqlserver deverá aparecer na listaGrupos de entrada:
- Clique no grupo de entradas
sqlserver. Seu console mostrará o seguinte:
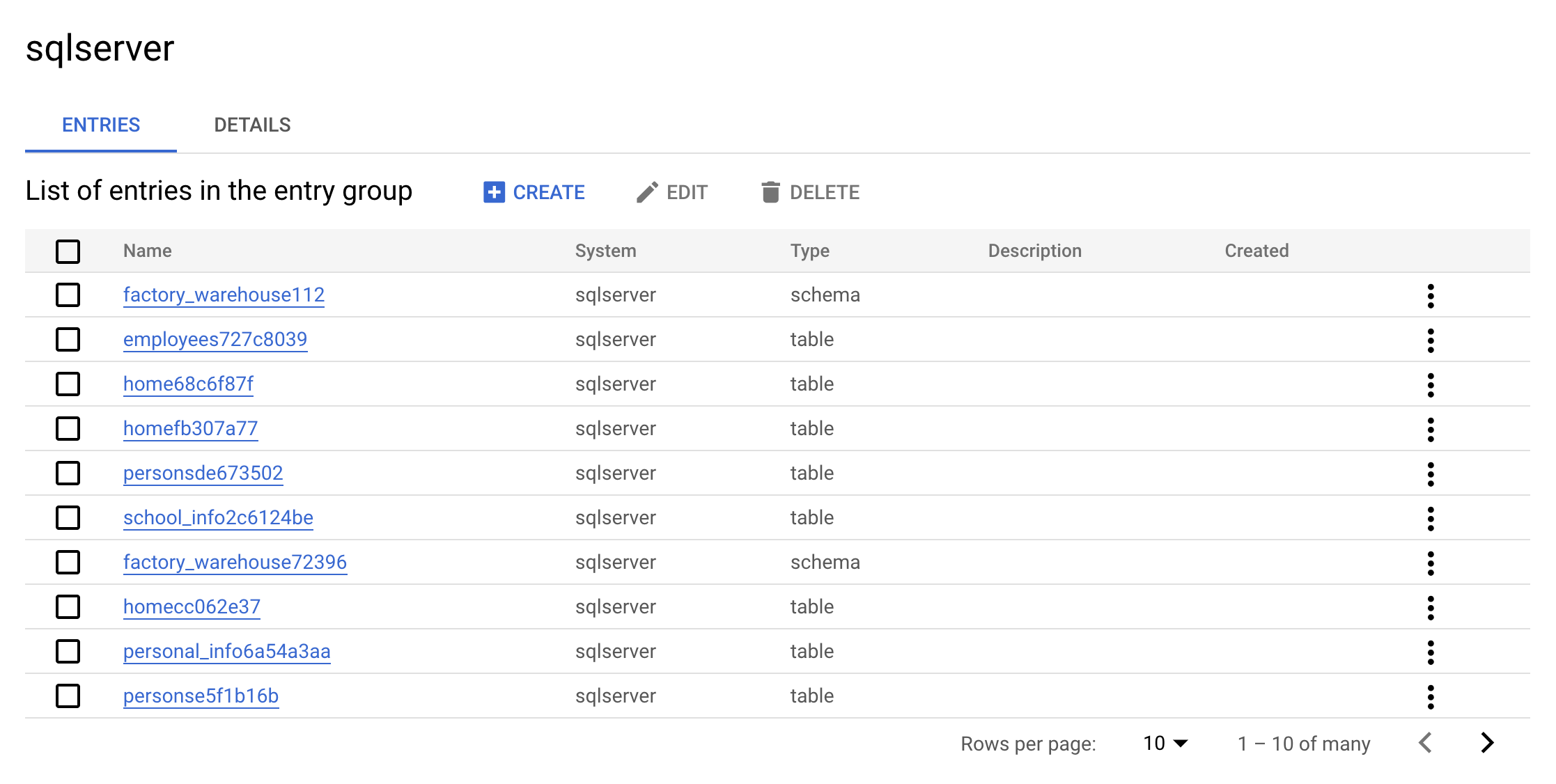
Esse é a vantagem real de um grupo de entradas: as entradas do sqlserver vão aparecer na interface.
- Clique em uma das entradas de
warehouse. Confira os detalhes e as tags da entrada personalizada.
Essa é a vantagem real do conector: ele permite pesquisar os metadados no Dataplex.
Limpar
- Para excluir os recursos criados, execute o seguinte comando, que removerá os metadados do SQL Server:
- Execute o contêiner mais limpo:
- Execute o seguinte comando para excluir o banco de dados do SQL Server:
-
No menu de navegação, clique em Dataplex.
-
Pesquise sqlserver.
Os modelos de tag do SQL Server não vão aparecer mais nos resultados:
Verifique se a seguinte resposta aparece no Cloud Shell antes de continuar:
Agora você aprenderá a fazer o mesmo com uma instância do PostgreSQL.
Tarefa 3. PostgreSQL para Dataplex
Criar o banco de dados do PostgreSQL
- Execute o seguinte comando no Cloud Shell para retornar ao diretório principal:
- Execute este comando para clonar o repositório do GitHub:
- Mude o diretório de trabalho para o do repositório clonado:
- Execute o seguinte comando para alterar de
us-central1para a região padrão atribuída a você:
- Execute o script
init-db.sh:
Isso cria e preenche a instância do PostgreSQL com um esquema aleatório. Esse processo pode levar de 10 a 15 minutos para ser concluído.
Error: Failed to load "tfplan" as a plan file for exibido, execute de novo o script init-db.
Logo depois, você receberá a seguinte resposta:
Clique em Verificar meu progresso para conferir o objetivo.
Configurar a conta de serviço
- Crie uma conta de serviço:
- Crie e faça o download da chave da conta de serviço:
- Agora adicione o papel de administrador do Data Catalog à conta de serviço:
Clique em Verificar meu progresso para conferir o objetivo.
Executar o conector do PostgreSQL para o Dataplex
Acesse este repositório do GitHub para criar o conector PostgreSQL por conta própria.
Para facilitar, você usará uma imagem Docker.
As variáveis necessárias foram geradas pela configuração do Terraform.
- Migre os diretórios para o local dos scripts do Terraform:
- Copie as seguintes variáveis de ambiente:
- Retorne ao diretório raiz do código de exemplo:
- Execute o conector:
Logo depois, você receberá a seguinte resposta:
Clique em Verificar meu progresso para conferir o objetivo.
Confira os resultados do script
-
Verifique se você está na página inicial do Dataplex.
-
Clique em Modelos de tag.
Os seguintes modelos de tag postgresql serão vão aparecer:

- Clique em Grupos de entrada.
O seguinte grupo de entradas postgresql vai aparecer:

- Clique no grupo de entradas
postgresql. Seu console mostrará o seguinte:
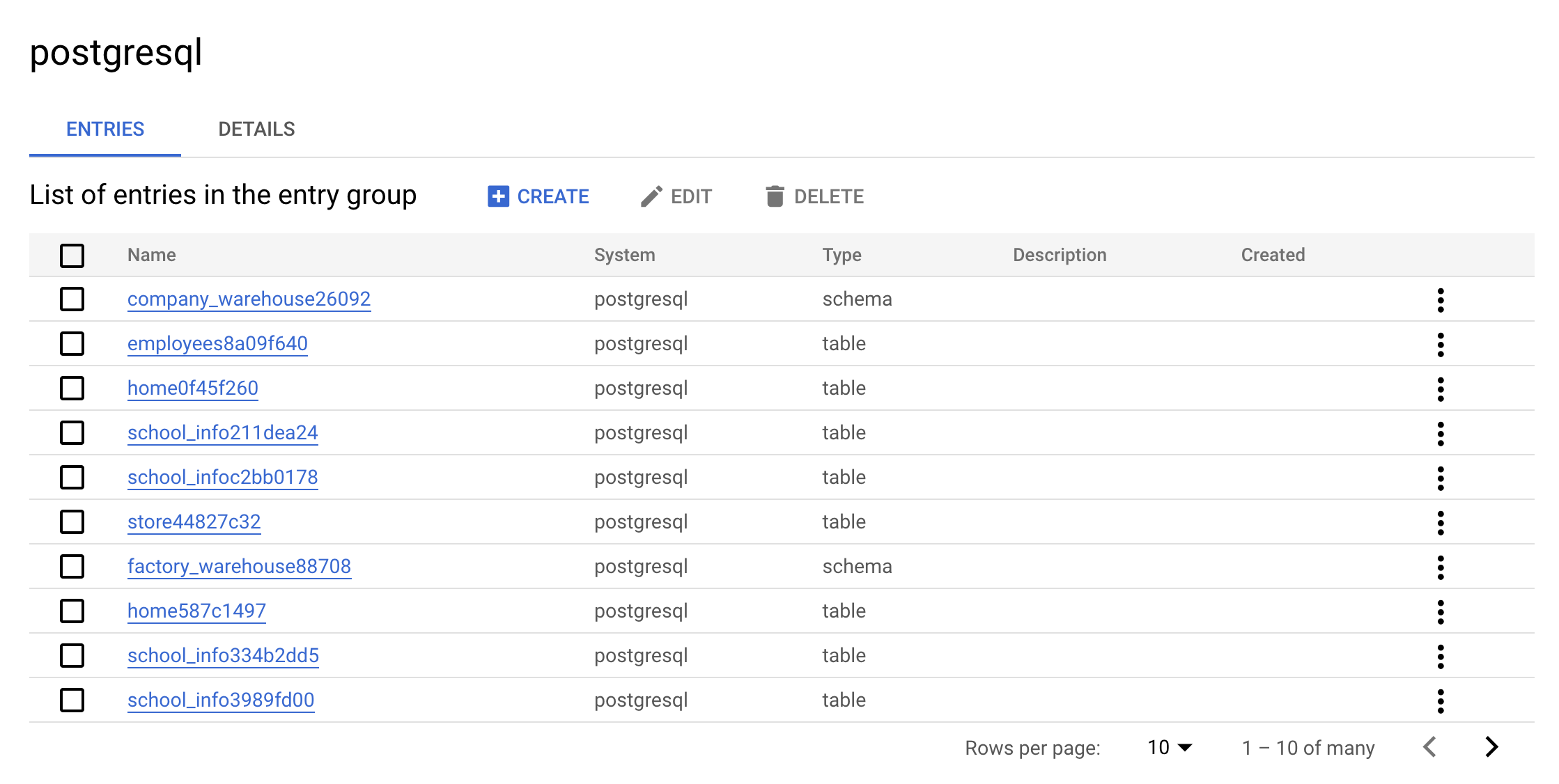
Essa é a vantagem real de um grupo de entradas: as entradas do postgresql são exibidas na interface.
- Clique em uma das entradas de
warehouse. Confira os detalhes e as tags da entrada personalizada:
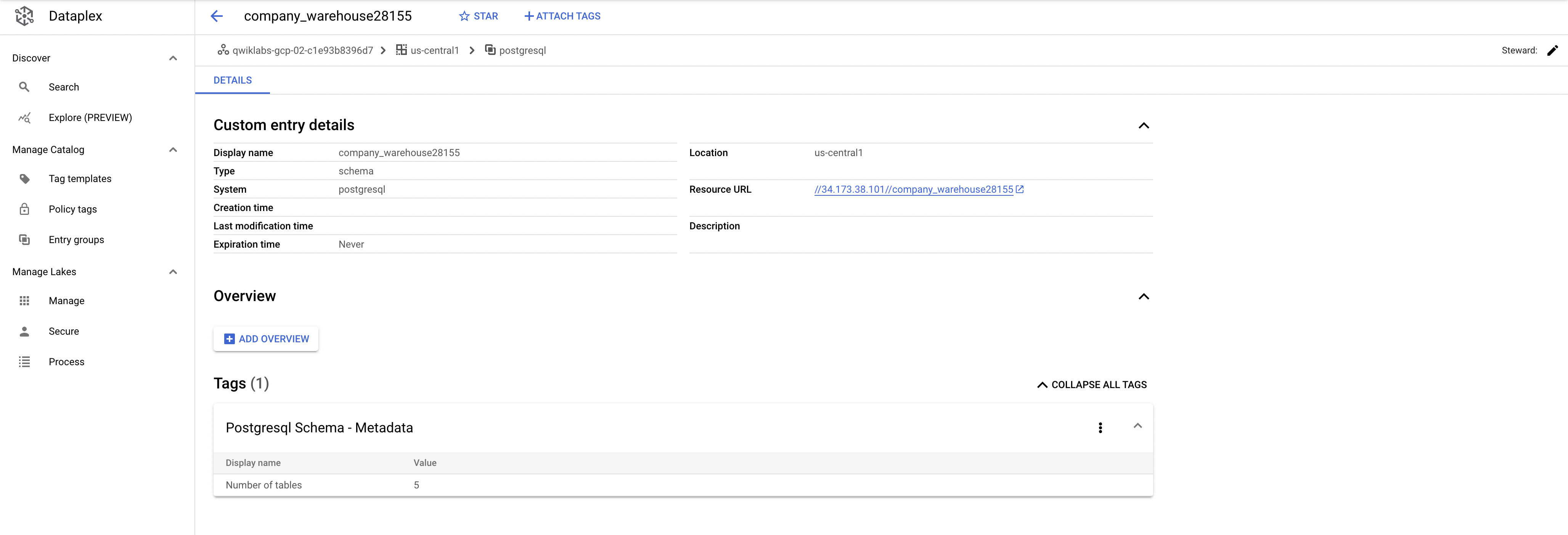
Essa é a vantagem real do conector: ele permite pesquisar os metadados no Dataplex.
Limpar
- Para excluir os recursos criados, execute o seguinte comando, que remove os metadados do PostgreSQL:
- Execute o contêiner mais limpo:
- Por último, exclua o banco de dados do PostgreSQL:
-
No menu de navegação, clique em Dataplex.
-
Pesquise PostgreSQL. Os modelos de tag do PostgreSQL não vão estar mais nos resultados:
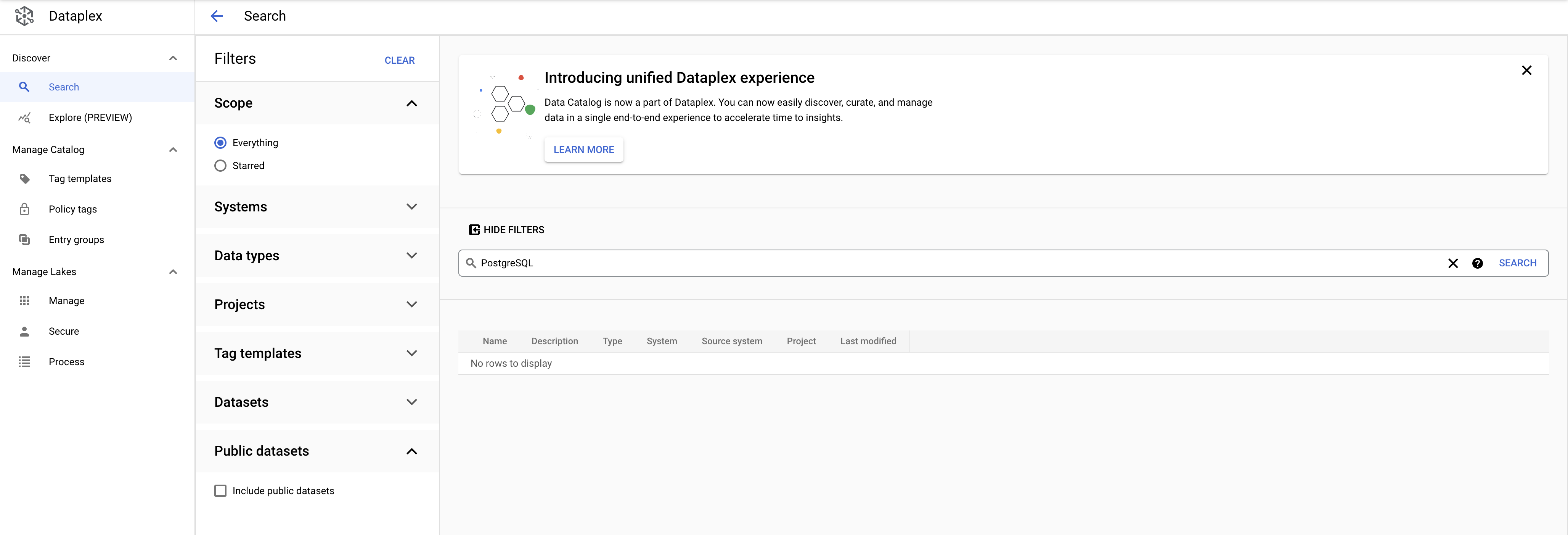
Verifique se a seguinte resposta aparece no Cloud Shell antes de continuar:
Agora você aprenderá a fazer o mesmo com uma instância do MySQL.
Tarefa 4. MySQL para Dataplex
Criar o banco de dados do MySQL
- Execute o seguinte comando no Cloud Shell para retornar ao diretório principal:
- Execute o seguinte comando para fazer o download dos scripts para criar e preencher a instância do MySQL:
- Mude o diretório de trabalho para o do repositório clonado:
- Execute o seguinte comando para alterar de
us-central1para a região padrão atribuída a você:
- Execute o script
init-db.sh:
Isso cria e preenche a instância do MySQL com um esquema aleatório. Depois de alguns minutos, você receberá a seguinte resposta:
Error: Failed to load "tfplan" as a plan file for exibida, execute de novo o script init-db.
Clique em Verificar meu progresso para conferir o objetivo.
Configurar a conta de serviço
- Execute o seguinte comando para criar uma conta de serviço:
- Crie e faça o download da chave da conta de serviço:
- Agora adicione o papel de administrador do Data Catalog à conta de serviço:
Clique em Verificar meu progresso para conferir o objetivo.
Executar o conector do MySQL para o Dataplex
Acesse este repositório do GitHub para criar o conector MySQL por conta própria.
Para facilitar a utilização, este laboratório usa uma imagem Docker.
As variáveis necessárias foram geradas pela configuração do Terraform.
- Migre os diretórios para o local dos scripts do Terraform:
- Copie as seguintes variáveis de ambiente:
- Retorne ao diretório raiz do código de exemplo:
- Execute o conector:
Logo depois, você receberá a seguinte resposta:
Clique em Verificar meu progresso para conferir o objetivo.
Confira os resultados do script
-
Verifique se você está na página inicial do Dataplex.
-
Clique em Modelos de tag.
Os seguintes modelos de tag do mysql vão aparecer:

- Clique em Grupos de entrada.
O seguinte grupo de entradas mysql vai aparecer:

- Clique no grupo de entradas
mysql. Seu console mostrará o seguinte:
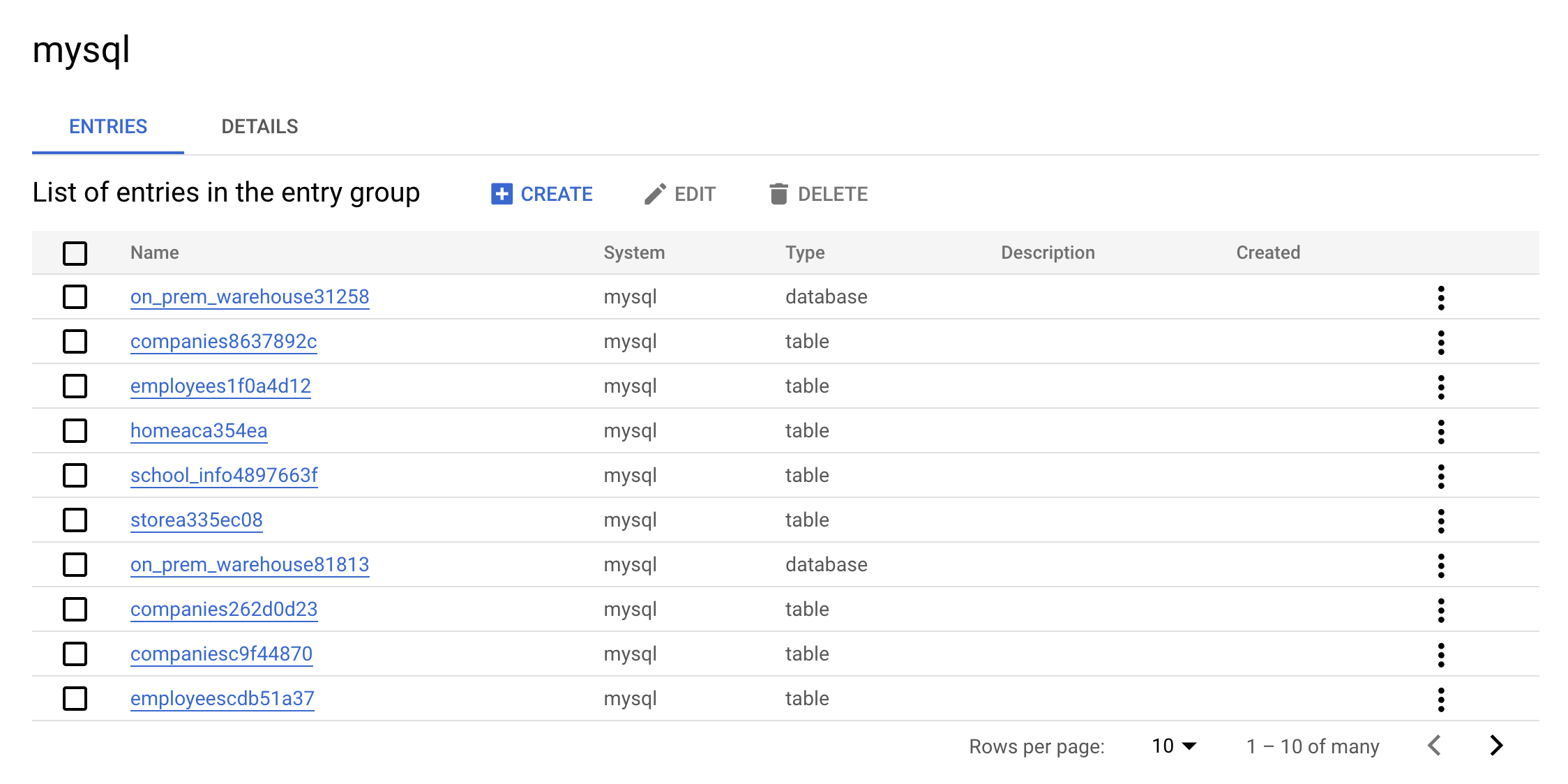
Essa é a vantagem real de um grupo de entradas: todas as entradas do MySQL vão aparecer na interface.
- Clique em uma das entradas de
warehouse. Confira os detalhes e as tags da entrada personalizada.
Essa é a vantagem real do conector: ele permite pesquisar os metadados no Dataplex.
Limpar
- Para excluir os recursos criados, execute o seguinte comando, que remove os metadados do MySQL:
- Execute o contêiner mais limpo:
- Por último, exclua o banco de dados do PostgreSQL:
-
No menu de navegação, clique em Dataplex.
-
Pesquise MySQL. Os modelos de tag do MySQL não vão aparecer mais nos resultados.
Verifique se a seguinte resposta aparece no Cloud Shell antes de continuar:
Parabéns!
Parabéns! Neste laboratório, você aprendeu como criar e executar os conectores MySQL, PostgreSQL e SQL Server para o Dataplex. Também aprendeu a pesquisar as entradas do SQL Server, PostgreSQL e MySQL no Data Catalog dentro do Dataplex. Com esse conhecimento, é possível criar seus conectores.
Conclusão do curso
Este laboratório autoguiado faz parte dos cursos BigQuery for Data Warehousing, BigQuery for Marketing Analysts e Data Catalog Fundamentals. Confira o catálogo do Google Cloud Ensina para acessar todos os cursos disponíveis.
Próximas etapas/Saiba mais
- Leia a Visão geral do Data Catalog.
- Saiba como pesquisar com o Data Catalog
- Leia o artigo "Visão geral de APIs e bibliotecas de cliente".
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 17 de outubro de 2023
Laboratório testado em 17 de outubro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.