チェックポイント
Create a new dataset
/ 25
Identify a key field in your ecommerce dataset
/ 25
Pitfall: non-unique key
/ 25
Join pitfall solution
/ 25
データ結合における問題のトラブルシューティングと解決
GSP412

概要
BigQuery は、Google が低価格で提供する NoOps、フルマネージドの分析データベースです。BigQuery では、インフラストラクチャを所有して管理したりデータベース管理者を置いたりすることなく、テラバイト単位の大規模なデータでクエリを実行できます。また、SQL が採用されており、従量課金制というメリットがあります。このような特徴を活かし、お客様は有用な情報を得るためのデータ分析に専念できます。
データテーブルを結合すると、データセットに関する有用な情報を取得できます。ただし、データを結合する際のよくある問題によって、不適切な結果を取得することになる場合があります。このラボでは、このような問題を回避する方法について詳しく学習します。結合のタイプ:
- クロス結合: 1 つ目のデータセットの各行と 2 つ目のデータセットの各行が結合され、すべての組み合わせが出力されます。
- 内部結合: 結果テーブルにレコードを表示するには、両方のテーブルにキー値が存在する必要があります。両方のテーブルでキー値が一致している場合のみ、レコードが結合された状態で表示されます。
- 左結合: 左側のテーブルの各行が結果に表示されます。一致するレコードが右側のテーブルにあるかどうかは問いません。
- 右結合: 左結合の逆です。右側のテーブルの各行が結果に表示されます。一致するレコードが左側のテーブルにあるかどうかは問いません。
結合の詳細については、結合のページをご覧ください。
ここでは、ecommerce データセットを使用します。このデータセットには、Google Merchandise Store に関する数百万件の Google アナリティクス レコードが含まれており、BigQuery に読み込まれています。このデータセットのコピーを使用して、フィールドや行からどのような分析情報が得られるのかを確認します。
クエリを理解、更新するために役立つ構文の情報については、標準 SQL のクエリ構文をご覧ください。
演習内容
このラボでは、以下のタスクを実行します。
- BigQuery を使用してデータセットを探索する
- データセット内の重複する行のトラブルシューティングを行う
- データテーブルを結合する
- 結合の各タイプについて理解する
設定
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
タスク 1. 新しいデータセットを作成してテーブルを保存する
BigQuery プロジェクトで、「ecommerce」という名前の新しいデータセットを作成します。
- プロジェクト ID の隣の 3 つの点をクリックして、[データセットを作成] を選択します。
![ハイライト表示された [データセットを作成] オプション](https://cdn.qwiklabs.com/E1Izps4nHGg93qwbX6%2BqQMiTUp13tvY0FIpZTm9PqSk%3D)
[データセットを作成する] ダイアログが開きます。
-
[データセット ID] に「
ecommerce」と入力します。 -
他の項目はデフォルト値のままにして、[データセットを作成] をクリックします。
左側のパネルで、対象のプロジェクトに ecommerce テーブルが表示されます。
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
タスク 2. BigQuery でラボのプロジェクトを固定する
シナリオ: e コマースのウェブサイトで販売されている各商品の在庫ストックレベルに関する新しいデータセットがチームから提供されます。あなたは、ウェブサイト上の商品について、また他のデータセットとの結合に使用できる可能性があるフィールドについて把握したいと考えています。
新しいデータセットを含むプロジェクトは data-to-insights です。
-
ナビゲーション メニュー
> [BigQuery] の順にクリックします。
[Cloud Console の BigQuery へようこそ] メッセージ ボックスが開きます。
-
[完了] をクリックします。
-
BigQuery の一般公開データセットは、デフォルトでは表示されません。一般公開データセット プロジェクトを開くには、「data-to-insights」をコピーします。
-
[+ 追加] > [名前を指定してプロジェクトにスターを付ける] の順にクリックしたら、「data-to-insights」名を貼り付けます。
-
[スターを付ける] をクリックします。
data-to-insights プロジェクトが [エクスプローラ] に表示されます。
タスク 3. フィールドを確認する
次に、クエリを作成してデータセットを分析するために使用できるウェブサイト上の商品とフィールドを確認します。
-
左側のペインの [リソース] セクションで、[
data-to-insights] > [ecommerce] > [all_sessions_raw] に移動します。 -
右側のクエリエディタで [スキーマ] タブをクリックして、フィールドと各フィールドの情報を表示します。
タスク 4. ecommerce データセットの主要なフィールドを特定する
商品とフィールドについて詳しく確認します。あなたは、ウェブサイト上の商品について、また他のデータセットとの結合に使用できる可能性があるフィールドについて把握したいと考えています。
レコードを調べる
このセクションでは、ウェブサイト上の商品名と商品 SKU の件数、およびそれらのフィールドのうち一意のものがあるかどうかを確認します。
- ウェブサイト上の商品名と商品 SKU の件数を確認します。BigQuery エディタに下のクエリをコピーして貼り付けます。
- [実行] をクリックします。
コンソール内のページ分けされた結果を見て、返されたレコードの合計数を確認します。
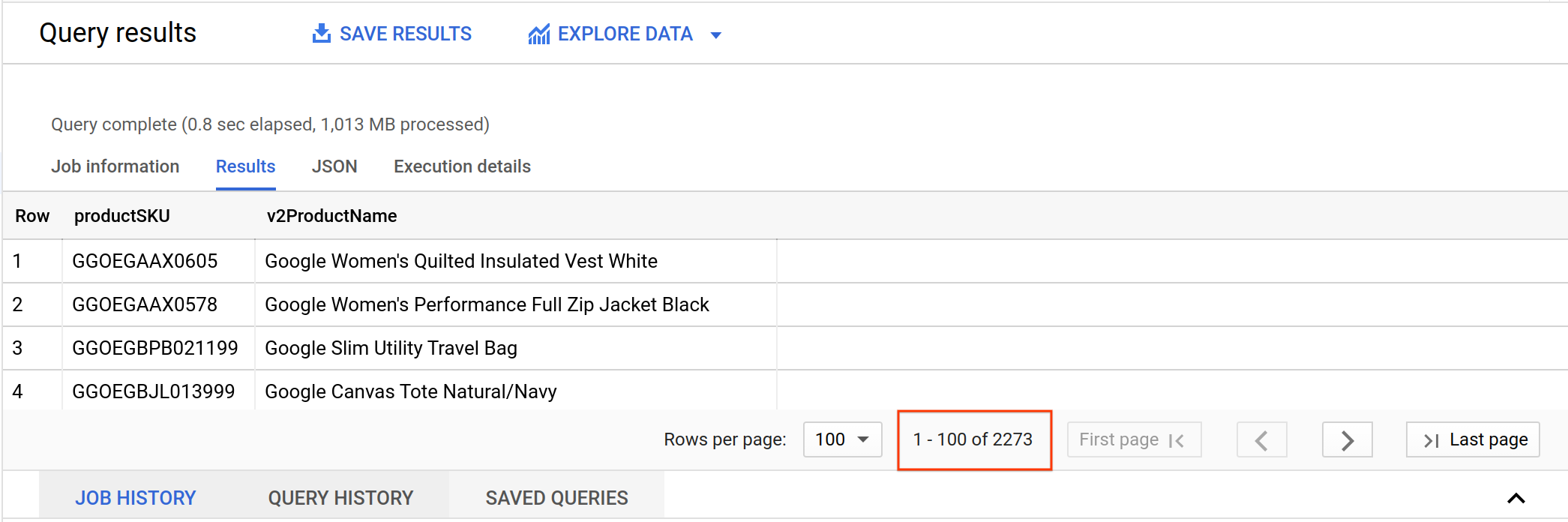
一意の商品 SKU は本当にこれほど多くあるのでしょうか。データ アナリストが最初に実行すべきクエリの 1 つは、データ値の一意性を調べるクエリです。
- 前のクエリを消去し、
DISTINCTを使用した以下のクエリを実行して、一意の SKU の数を表示します。
SKU と名前の関係を調べる
複数の SKU を持つ商品と、複数の商品名を持つ SKU を特定します。
- 前のクエリを消去して以下のクエリを実行し、商品名に複数の SKU が割り当てられているかを確認します。STRING_AGG() 関数を使用して、1 つの商品名に関連付けられているすべての商品 SKU をカンマ区切り値に集約します。
- [実行] をクリックします。
結果:
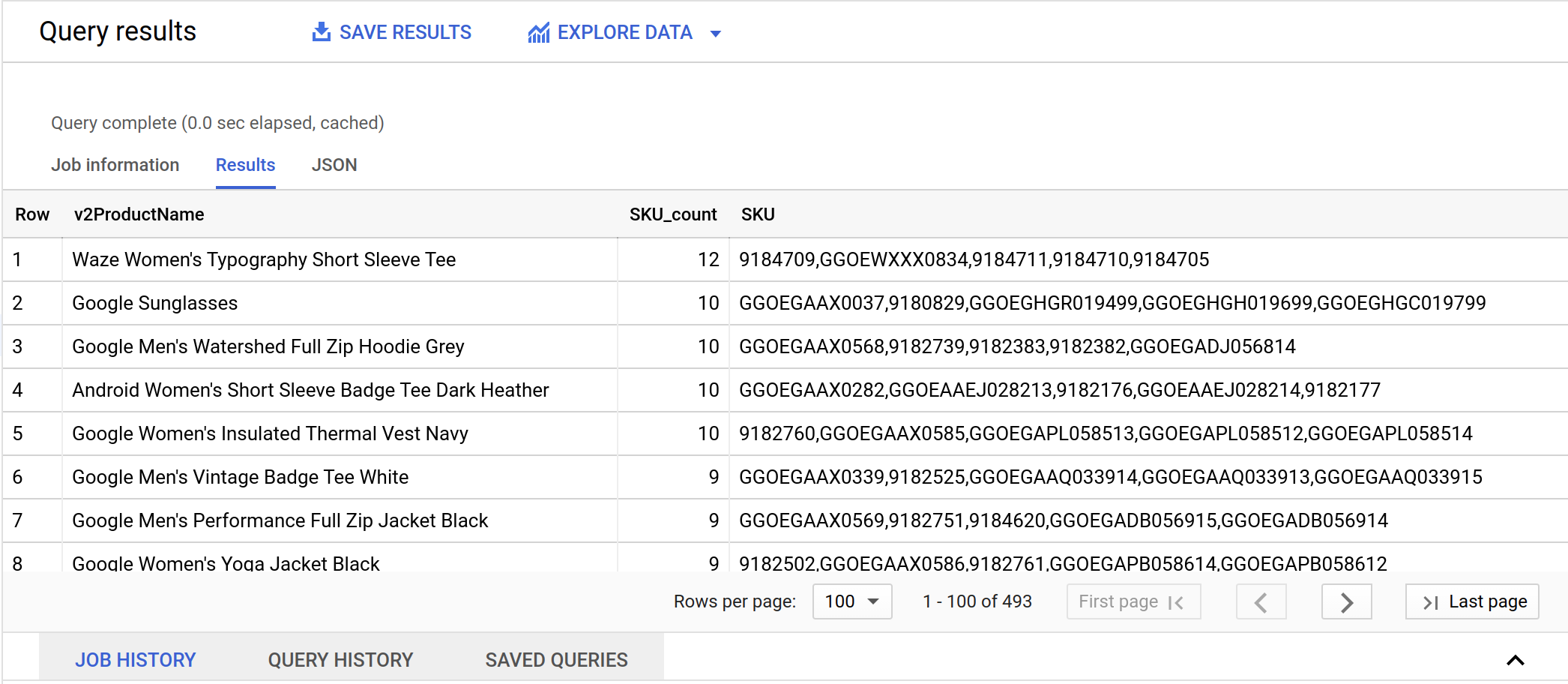
この e コマースサイトのカタログを見ると、いくつかの商品名には複数のオプション(サイズ、色)があることがわかります。それらは、別々の SKU として販売されています。
クエリの結果から、場合によっては 1 つの商品に 12 件もの SKU があることがわかりました。では、1 つの SKU についてはどうでしょうか。1 つの SKU が複数の商品に割り当てられていることもあるのでしょうか。
- 前のクエリを消去し、以下のクエリを実行して確認します。
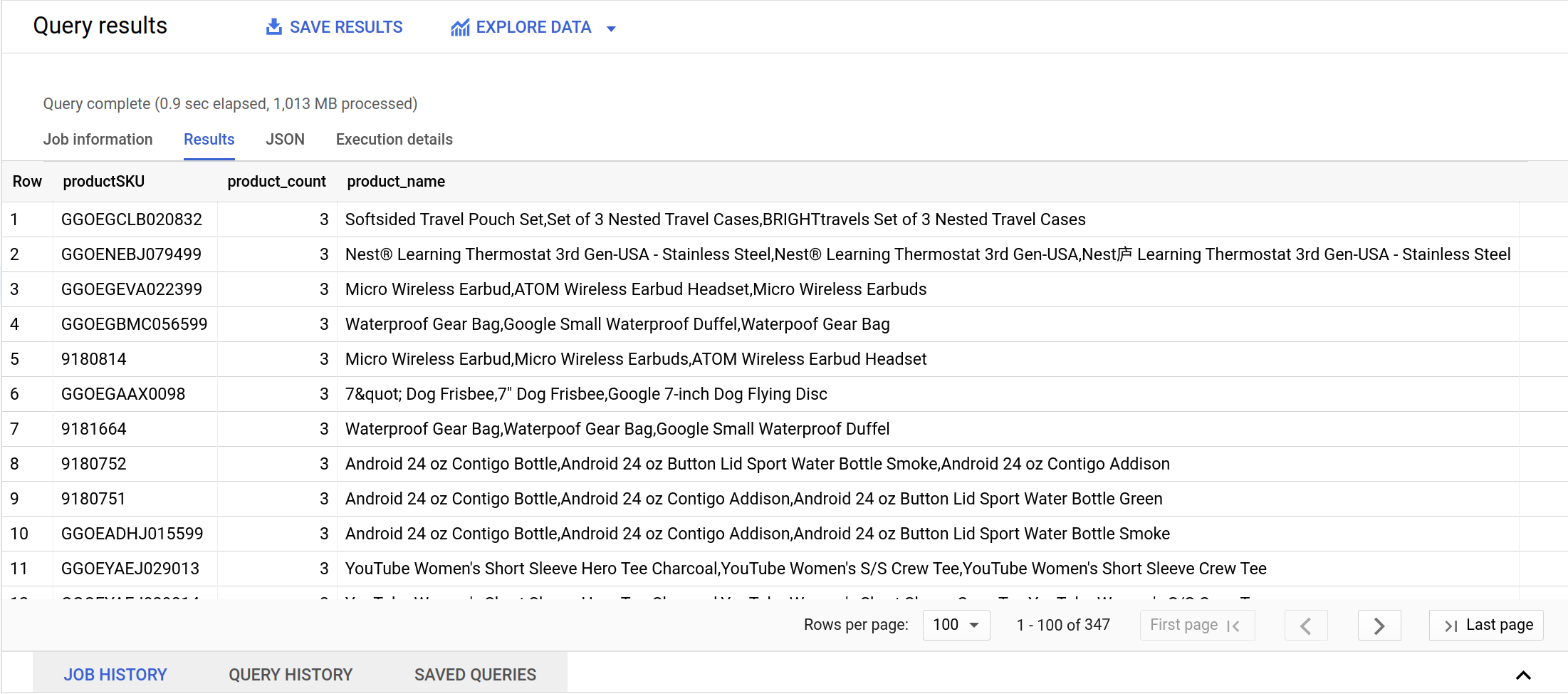
次のセクションでは、この多対多のデータの関係が問題になる理由を確認します。
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
タスク 5. 問題: キーが一意でない
SKU は、在庫のトラッキングで 1 つの商品のみを一意に特定するためのもので、ここでは他のテーブルの情報を検索する際の基本的な結合条件となります。これから見ていくように、一意でないキーが存在すると、データに関する深刻な問題が発生する可能性があります。
-
クエリを作成して、SKU「
GGOEGPJC019099」にひも付けられたすべての商品名を特定します。
解答例:
- [実行] をクリックします。
|
v2ProductName |
productSKU |
|
7" Dog Frisbee |
GGOEGPJC019099 |
|
7" Dog Frisbee |
GGOEGPJC019099 |
|
Google 7-inch Dog Flying Disc Blue |
GGOEGPJC019099 |
クエリの結果によると、同じ商品に 3 つの異なる名前が付いています。この例では、名前に特殊文字が含まれているものが 1 つと、名前がわずかに異なるものが 1 つあります。
ウェブサイトのデータを商品在庫と結合する
複数の商品に 1 つの SKU が関連付けられているデータセットを結合した場合の影響を確認しましょう。まず、商品在庫のデータセット(products テーブル)を参照して、この SKU がテーブル内で一意かどうかを確認します。
- 前のクエリを消去し、以下のクエリを実行します。
結合における問題: 予期せず多対 1 の関係になっている SKU
現在、2 つのデータセットがあります。1 つは在庫ストックレベルのデータセット、もう 1 つはウェブサイトの分析用のデータセットです。在庫のデータセットをウェブサイトの商品名および SKU と結合し、ウェブサイトで販売されている各商品に関連付けられている在庫ストックレベルを取得します。
- 前のクエリを消去し、以下のクエリを実行します。
次に、上のクエリを拡張して、商品ごとの在庫の合計を単純に計算します。
- 前のクエリを消去し、以下のクエリを実行します。
現在のところ、在庫が 3 倍になってしまいました(154 x 3 = 462)。これは、意図しないクロス結合と呼ばれています(このトピックについては後でまた触れます)。
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
タスク 6. 結合における問題の解決策: 結合前に一意の SKU を使用する
数字が 3 倍にならないようにするにはどうすればよいでしょうか。まず、他のデータセットと結合する前に、ウェブサイトから一意の SKU のみを取得する必要があります。
複数の商品名(7" Dog Frisbee など)に同じ 1 つの SKU が関連付けられている場合があることはすでに確認しました。
- 想定されるすべての商品名を 1 つの配列にまとめます。
これで、すべての商品名に行を割り当てる代わりに、一意の SKU ごとにのみ行を割り当てることができました。
- 商品名の重複を排除したい場合は、次のように、LIMIT を使用して配列の要素数を制限することもできます。
結合における問題: 結合後にデータのレコードが失われる
ここでは、商品在庫のデータセットに対してもう一度結合します。
- 前のクエリを消去し、以下のクエリを実行します。
データセットの結合後に 819 件の SKU が失われたことがわかります。より具体的な情報をフィールド(各データセットから 1 つの SKU 列)に追加して調査します。
- 前のクエリを消去し、以下のクエリを実行します。
これらの 1,090 件のレコードの SKU は、結合後、両方のデータセットに存在しているようです。失われたレコードを見つけるにはどうすればよいでしょうか。
結合における問題の解決策: 適切な結合のタイプを選択し、検索条件に NULL を指定する
デフォルトの結合のタイプは内部結合です。これは、結合された左右両方のテーブルで SKU が一致する場合のみレコードを返します。
- 前のクエリを修正して別の結合のタイプを使用し、商品在庫の SKU のレコードと一致するものがなくても、ウェブサイトのテーブルの全レコードを取得するようにします。使用できる結合のタイプ: 内部結合(INNER JOIN)、左結合(LEFT JOIN)、右結合(RIGHT JOIN)、完全結合(FULL JOIN)、クロス結合(CROSS JOIN)
解答例:
- [実行] をクリックします。
左結合を適切に使用し、元のウェブサイトの SKU 1,909 件がすべて結果に返されました。
商品在庫のセットから何件の SKU が失われましたか。
- クエリを作成して、在庫テーブルの NULL 値を検索条件に指定します。
解答例:
- [実行] をクリックします。
質問: 不足している商品はいくつですか。
解答: 819 件の商品が商品在庫データセットから失われています(SKU が NULL)。
- 前のクエリを消去して以下のクエリを実行し、ウェブサイトのデータセットから特定の SKU のうち一つを使用して確認します。
逆の場合についてはどうでしょうか。商品在庫データセットには存在するものの、ウェブサイトから失われているデータはありますか。
- 別の結合のタイプを使用してクエリを作成し、調査します。
解答例:
- [実行] をクリックします。
解答: はい。2 つの商品 SKU がウェブサイトのデータセットから失われています。
次に、商品在庫データセットから他のフィールドを追加して詳細を確認します。
- 前のクエリを消去し、以下のクエリを実行します。
以下の商品が ecommerce ウェブサイトのデータセットから失われている理由は何ですか。
|
website_SKU |
SKU |
name |
orderedQuantity |
stockLevel |
restockingLeadTime |
sentimentScore |
sentimentMagnitude |
|
null |
GGOBJGOWUSG69402 |
USB wired soundbar - in store only |
10 |
15 |
2 |
1.0 |
1.0 |
|
null |
GGADFBSBKS42347 |
PC gaming speakers |
0 |
100 |
1 |
null |
null |
解答例:
- 1 つは新商品(注文なし、感情スコアなし)、1 つは「店舗のみ」に存在する商品
- もう 1 つは、まだ注文のない新商品
新しい商品がウェブサイトのデータセットに表示されない理由は何ですか。
- ウェブサイトのデータセットは、顧客による過去の注文の取引であり、まだ 1 つも販売されていない新商品は、閲覧または購入が発生するまでウェブ分析に表示されません。
ウェブサイトまたは在庫にない商品をすべて 1 つのクエリで取得するにはどうすればよいですか。
- 別の結合のタイプを使用してクエリを作成します。
解答例:
- [実行] をクリックします。
819 + 2 = 821 件の商品 SKU が表示されます。
左結合と右結合を組み合わせると完全結合になり、結合キーが一致するかどうかにかかわらず、両方のテーブルからすべてのレコードが返されます。その後、どちらか一方で一致しないレコードを除外します。
結合における問題: 意図しないクロス結合
データテーブルのキー同士の関係(1:1、1:N、N:N)を理解していないと、予期しない結果が返される場合があります。また、クエリのパフォーマンスが大幅に低下する可能性もあります。
最後の結合のタイプはクロス結合です。
サイト全体の割引率を含む新しいテーブルを作成します。この割引率は、「セール」のカテゴリに含まれるすべての商品に適用されます。
- 前のクエリを消去し、以下のクエリを実行します。
左側のパネルで、プロジェクトの [リソース] セクションとデータセットに site_wide_promotion が表示されます。
- 前のクエリを消去して次のクエリを実行し、セールに含まれる商品の数を確認します。
割引テーブルに予期せず複数のレコードが追加された場合の影響を確認しましょう。
- 前のクエリを消去して次のクエリを実行し、プロモーション テーブルに 2 つのレコードを追加します。
次に、プロモーション テーブルのデータの値を確認します。
- 前のクエリを消去し、以下のクエリを実行します。
レコードは何件返されましたか。
解答: 3
82 件すべてのセール商品に割引を適用するとどうなりますか。
- 前のクエリを消去し、以下のクエリを実行します。
商品は何件返されましたか。
解答: 82 件ではなく 246 件返されます。開始時にテーブルに存在した元のレコード数より多くなっています。
1 つの商品 SKU を確認して、根本的な原因を調査しましょう。
- 前のクエリを消去し、以下のクエリを実行します。
クロス結合によってどのような影響がありましたか。
解答: 3 つの割引コードがクロス結合されるため、元のデータセットが 3 倍になります。
解決策は、結合する前にデータの関係性を理解し、キーが一意ではない場合があることを想定することです。
[進行状況を確認] をクリックして、目標に沿って進行していることを確認します。
お疲れさまでした
これでこのラボは完了です。重複しているレコードを特定し、各結合のタイプを使用する状況を理解することで、SQL の結合における深刻な問題を確認しました。
クエストを完了する
このセルフペース ラボは、「BigQuery for Data Warehousing」クエストの一部です。クエストとは学習パスを構成する一連のラボのことで、完了すると成果が認められて上のようなバッジが贈られます。バッジは公開して、オンライン レジュメやソーシャル メディア アカウントにリンクできます。このラボの修了後、次のクエストに登録すれば、すぐにクレジットを受け取ることができます。受講可能なその他の Qwiklabs のクエストについては、Google Cloud Skills Boost カタログをご覧ください。
次のラボを受講する
BigQuery での JSON、配列、構造体の操作などに進んでクエストを続けるか、以下のおすすめのラボをご確認ください。
次のステップと詳細情報
-
すでに Google アナリティクス アカウントをお持ちで、BigQuery で独自のデータセットをクエリするには、こちらのエクスポート ガイドの手順を実施してください。
-
クエリ計算の最適化についてのガイダンスを提供するベスト プラクティスをご確認ください。
-
JOIN を使用したその他の SQL 構文をお試しになりたい場合は、BigQuery の JOIN に関するドキュメントをご確認ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 5 月 10 日
ラボの最終テスト日: 2023 年 5 月 10 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。